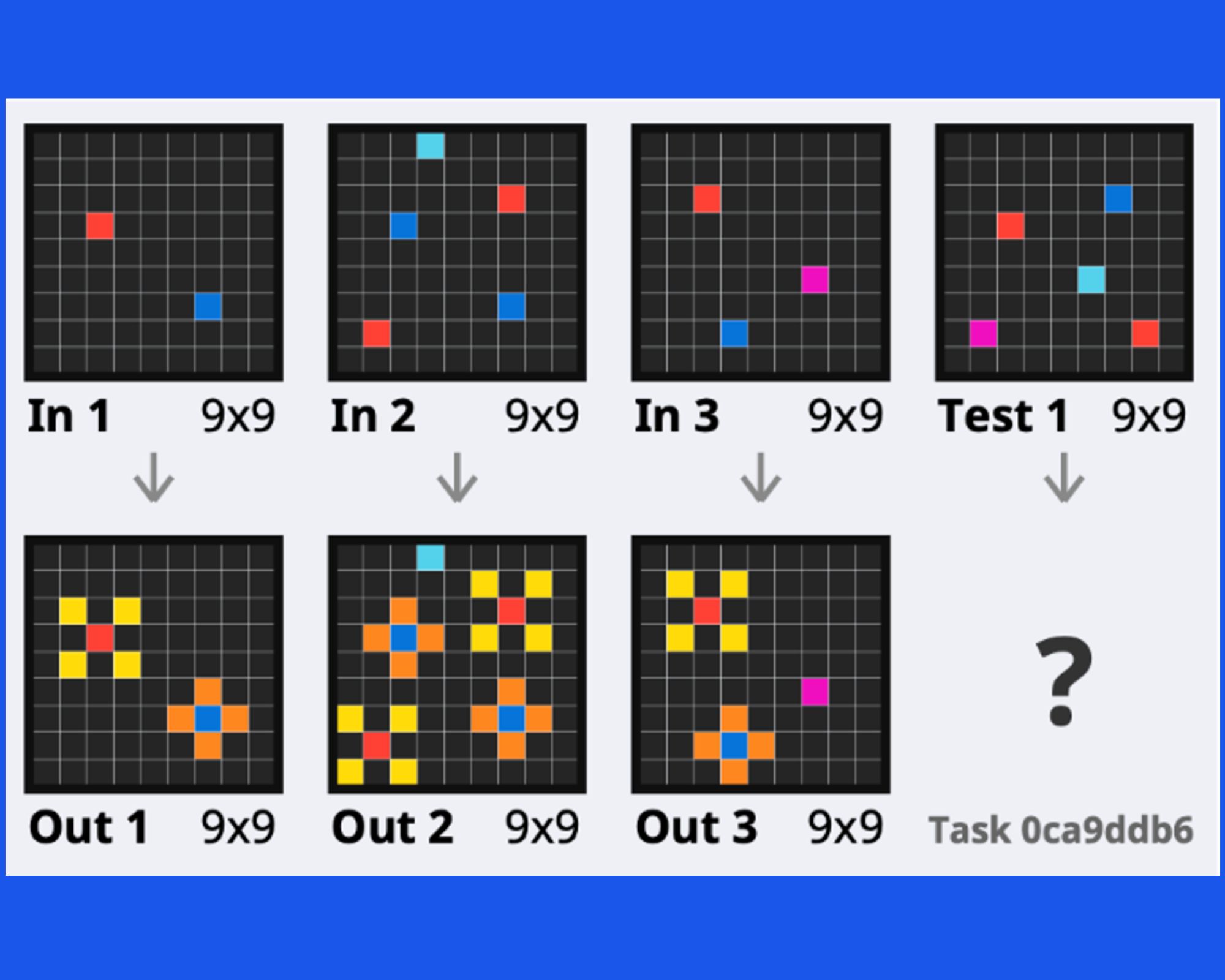
Towards broad generalization in machines
22 April 2024
Dr Romit Samanta, NIHR Clinical Lecturer in Intensive Care Medicine, University of Cambridge
17 May 2022

Acute respiratory distress syndrome (ARDS) affects one in 10 critical care patients. It is a condition in which the lungs cannot provide the body’s vital organs with enough oxygen; it is often a complication of a serious illness or infection and is fairly common, but under recognised.
Mortality from severe ARDS is approximately 40%. So, when treating these patients, you would see just over half of them get better. Some may be talking to you one day before needing a ventilator the next, and sadly dying a few days later, despite your best efforts. Doctors saw more people suffering from ARDS as a result of COVID-19 infection, and often it seemed like, as a doctor, everything you tried did nothing.
We have seen incredible advances in other medical fields over 50 years, but the percentage of people dying from ARDS has not changed and it remains the biggest problem in intensive care medicine. Treatments have been developed that work in a petri dish and in animals, but we can’t get them to work in humans because we simply don’t understand the relevant biology.
I decided to become a clinical academic trainee because I was frustrated by repeated failures of promising treatments for critically unwell patients in clinical trials. I’m using machine learning techniques to tap into the wealth of data from different studies and explain the underlying biological processes in groups of patients, which are currently poorly understood, resulting in failure to find new treatments.
Using data to solve a deadly problem
As a clinical academic I work clinical shifts but have the ‘brain-space’ to teach and use new research methods, techniques and tools. One area of interest has been machine learning and how to program, using Python, which I learned on the Accelerate Programme for Scientific Discovery mid-way through my PhD.
Learning Python has enabled me to analyse a vast amount of data from ARDS and sepsis studies in the UK, as well as randomised control trials, using data science techniques to identify different subgroups of patients and understand how their biology relates to disease progression. I sort datasets into a network or topology and then look at how different features of patients change in that network to see if there are any distinctive subtypes, or endotypes. If I find these, I’m able to look at biological differences between them and then use other types of data to corroborate my findings.
Using machine learning has led to insights into patient outcomes, and some of them are quite unexpected. My thesis attempted to address heterogeneity and explored the underlying biology by using an integrated, unsupervised bioinformatics approach to describe different mechanistic subtypes, or endotypes, of ARDS.
These endotypes were derived from analysis of data collected by three UK-based studies. I used a combination of automated clustering methods and network analysis tools to integrate blood biomarkers and gene expression data and define distinct endotypes of ARDS.
In patients with influenza, we found that for some patients ARDS was characterised by processes associated with leaky blood vessels in the their lungs, whilst others showed activation of different parts of the immune system. What surprised us was how patients who appeared critically unwell and needed a ventilator had different outcomes if they were associated with different endotypes.
Identifying the biological reasons why some patient groups that do well and some do not is important, as it could allow doctors to give targeted drugs to patients that have everything to gain from a particular intervention, while avoiding using them for patients whom they might make sicker. It could also lead to drugs that target specific biological mechanisms. While this is a long way from being validated, seeing that such personalised medicine may be on the horizon is exciting.
Putting research into practice
Machine learning is undoubtedly revolutionising healthcare, but there are several challenges to overcome. One is them is that intensive care data can be difficult for programs to interpret. Despite being rich in information, healthcare records are often full of shorthand expressions, acronyms and annotations, which doctors and nurses can easily decode and explain, but when read by machine learning programs, the data can be misinterpreted. Because of this, the records are not necessarily a good substrate for machines to understand a patient’s condition or why decisions have been made. Currently, the only way of overcoming this problem, is to manually visualise and check the data.
Even with this manual process, it is hard to rely on clinical datasets as test results, for example, they do not explain why patients become sick in the first place. It is also hard to place trust in machine learning algorithms that have been trained on extensively curated and cleaned data but not in a live healthcare setting where there is so much at stake.
The ultimate aim
The goal of understanding how to treat patients with ARDS gained a new level of urgency with the arrival of COVID-19, when the public became aware of thousands of patients dying on ventilators.
My research in ARDS continues and now also incorporates COVID, so I’m applying what I’ve found to COVID datasets. The pandemic has certainly sparked more interest in ARDS both in the UK and across the world and public datasets generated during this time will be an ongoing resource and ultimately benefit patients with and without COVID-19.
The ultimate goal is phenotyping – working out the exact underlying physical processes and biology of patients – so that intensive care clinicians will be able to work out the best trajectory for individuals based on features detected from simple blood tests that could measure genes or proteins in the blood.
While this may be around 20 years away, my research is part of a growing body of work that will help doctors treat ARDS more effectively, and hopefully end 50 years of limited progress in this area of intensive care medicine.
Dr Romit Samanta, NIHR Clinical Lecturer in Intensive Care Medicine, University of Cambridge (May 2022)
22 April 2024

18 March 2024

4 March 2024

19 February 2024