Towards broad generalization in machines
22 April 2024
Diana Robinson, University of Cambridge
01 February 2022
Accelerate spark data science residency
Significant postoperative bleeding is a common and sometimes fatal complication of heart surgery. Deciding which treatment is needed to stop the bleeding is difficult, as there are several factors that influence why bleeding occurs, including characteristics specific to the individual patient, interventions that are taken to prepare the patient for surgery, the type of surgery, and how the various interventions in the operating room have gone. There are 12 different clotting factors in the blood that all influence each other and need to be at the correct levels to make the chemical reactions that allow the blood to clot. This ‘coagulation cascade’ means that the choice of which blood product to transfuse is a difficult one, which involves many different tests and specialist clinicians. If a patient is bleeding profusely, it could be that they need more stitches, or it might mean that the components of the blood are not at the right levels to form a clot. Consequently, there are two main types of interventions to stop postoperative bleeding: further surgery, or transfusion which can include blood products or coagulant medications.
Whether to intervene with medications, transfusions, or surgery is just one of many critical decisions made by teams of different specialists caring for a patient, who draw upon observations, specialised information and their own experience.
Each of these interventions comes with trade-offs and risks to the patient, such as infection, and considerations at an institutional level, such as blood inventory management and use of theatre time and space, plus the consequences for delaying other patients. These risks and trade-offs are managed by a team of clinicians from different specialities who observe the patient with different frequencies and incorporate specific data and tests. To make the best decision for the patient, the process must involve coming to agreement and incorporating as much of the available data as possible within tight timeframes.
Collecting and Analysing Data from the Clinical Context
My research focuses on helping clinicians make data-driven decisions around postoperative bleeding by harnessing the power of artificial intelligence. As a human-computer interaction researcher, my work started with a field study of postoperative bleeding decisions in context at a specialist heart and lung hospital in Cambridge and involved remote interviews and targeted observations in the ICU (working around the constraints of the covid pandemic).
After completing this initial fieldwork and acquiring a dataset containing 20000 patient observations, I attended the Accelerate-Spark Data for Science Residency Programme, which helped me get to grips with practical data science processes like data cleaning. I had no previous experience with this, but it is essential for getting data into a usable format in order to visualise, analyse and start to build AI models.
The instructors on the course did lots of live coding of examples of data cleaning tasks, visualisation, and analysis, which was invaluable because it taught me a real time data science workflow, which involves looking up information on Stack Overflow, for example. Learning how to search for new functions and fix errors in the code was empowering as it gave me the tools to explore and experiment on my own. The programme also opened up new possibilities to me for how to visualise data and taught me to use tools like Jupyter Notebook, which enabled me to annotate my code to communicate analysis to my advisers and collaborate with them easily.
Now I am working on identifying which variables or combinations of variables (such as amount of bleeding at different timescales or type of surgery or patient characteristics like age or BMI) are predictive of a patient needing to be returned to theatre for further surgery, so I can build a probabilistic model using these features. A probabilistic machine learning approach allows for incorporation of uncertainty estimates in decisions which is the focus of my work.
Leveraging Past Cases and Visualising Uncertainty
My goal is to create modelling tools that clinicians can use, but the probabilistic programming languages that I am going to be using in my research are often unintuitive to non-statisticians. The next challenge will be to build an intuitive interface to help them visualise and reason with the uncertainty around sending a patient back to theatre and do scenario analysis on possible interventions.
As an endpoint, I envisage the tool being used at the bedside on a hospital computer, so it could be used as a convening tool by specialists. For example, it could prove helpful to discuss risks and priorities as well as explore possible trajectories for a patient during a multidisciplinary team meeting. In my PhD work, I will not be deploying this tool in realtime but will be experimenting with it in a controlled setting by asking clinicians to work through case studies with the assistance of the tool and provide feedback on the design and use.
Having the full institutional history of patient data to draw upon in decision making is one advantage of AI that clinicians are keen to embrace. I hope that the final iteration of the tool will not only give clinicians access to a wealth of case histories, but make it possible for them to create their own models of the data by putting together their assumptions and then running the inference to see the consequences for an individual patient trajectory.
Making a decision harnessing all of the data available could help find patterns that could not be seen by an individual clinician or a set of clinicians just drawing on their own experience. The goal is to empower clinical domain experts with tools from statistics and computer science in order for them to get the most out of their data at the bedside and make the best possible decisions.
Diana Robinson (February 2022)
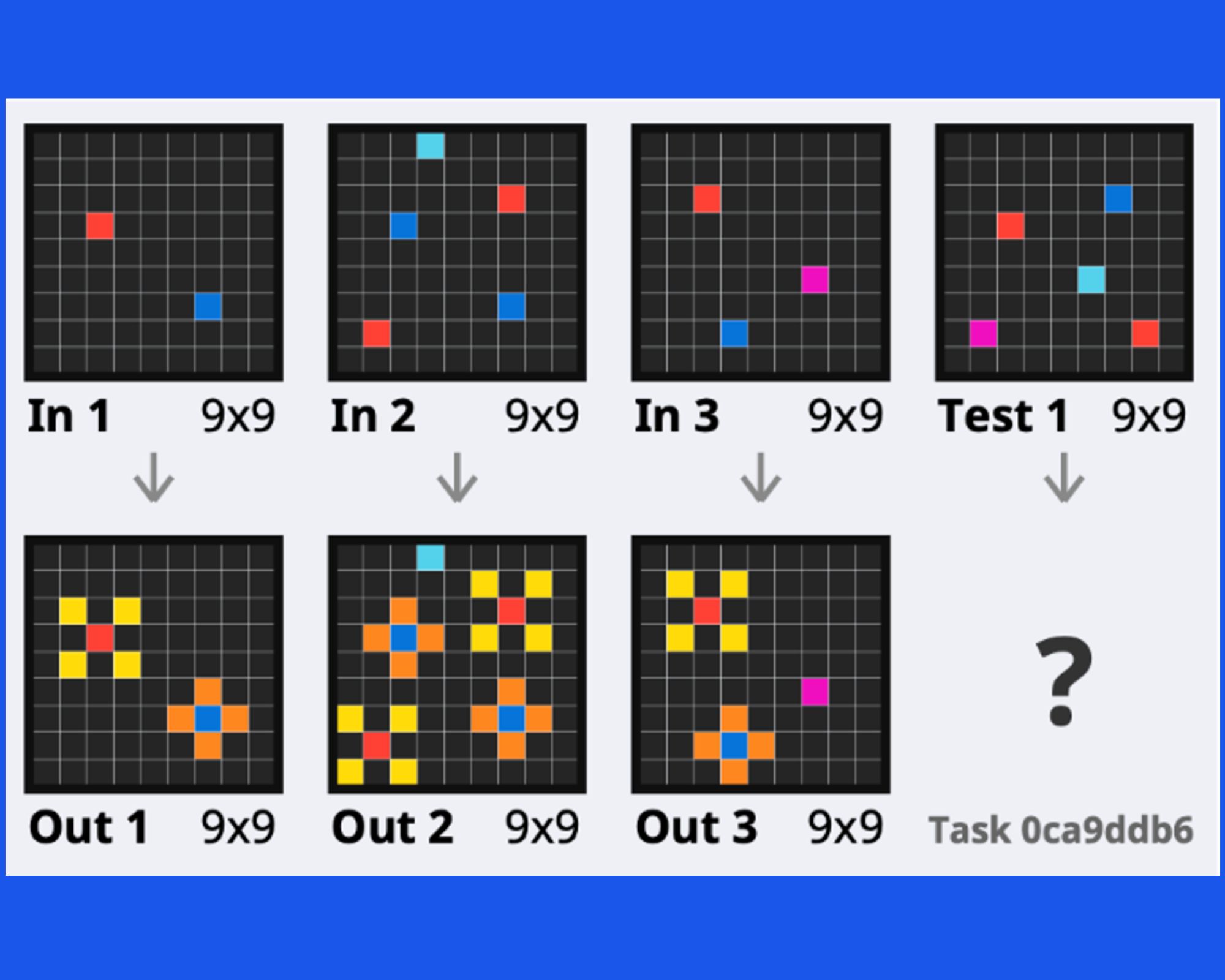
22 April 2024

18 March 2024

4 March 2024

19 February 2024