
How can we … use AI to redesign crutches?
27 June 2024
Jessica Montgomery, University of Cambridge
22 December 2021
Accelerate spark data science residency
On 19 November, Accelerate brought together researchers from across Cambridge to share perspectives on how AI is supporting their work. This post summarises some of the key points from discussions.
Researchers today have access to more and larger datasets than ever before. This data comes from large-scale scientific studies, from the digital mediation of daily activities, and from new approaches to simulation that generate synthetic datasets. Amidst this sea of data, the challenge is to make these vast datasets ‘drinkable’. To make this data manageable, researchers need new tools that can interrogate a greater range of data types from a wider range of data sources, extracting insights in support of scientific progress.
In this context, there has been great enthusiasm for the use of machine learning and artificial intelligence as enablers of scientific discovery. These methods are already being deployed in the service of science – on this blog, we’ve featured posts about their use in cell biology, physics, and genetics– and high-profile AI-enabled discoveries have generated excitement about the future of AI for science. At the same time, we’ve seen a range of ways in which AI can fail in deployment: whether in producing health diagnostic tools that fail in clinical settings; introducing biases into datasets that can skew scientific interpretations; or through their ‘brittleness’ in deployment. AI can be a powerful analytical tool, but making effective use of it requires careful examination of the challenge at hand and the context in which it will be deployed, which in turn requires expertise from different domains.
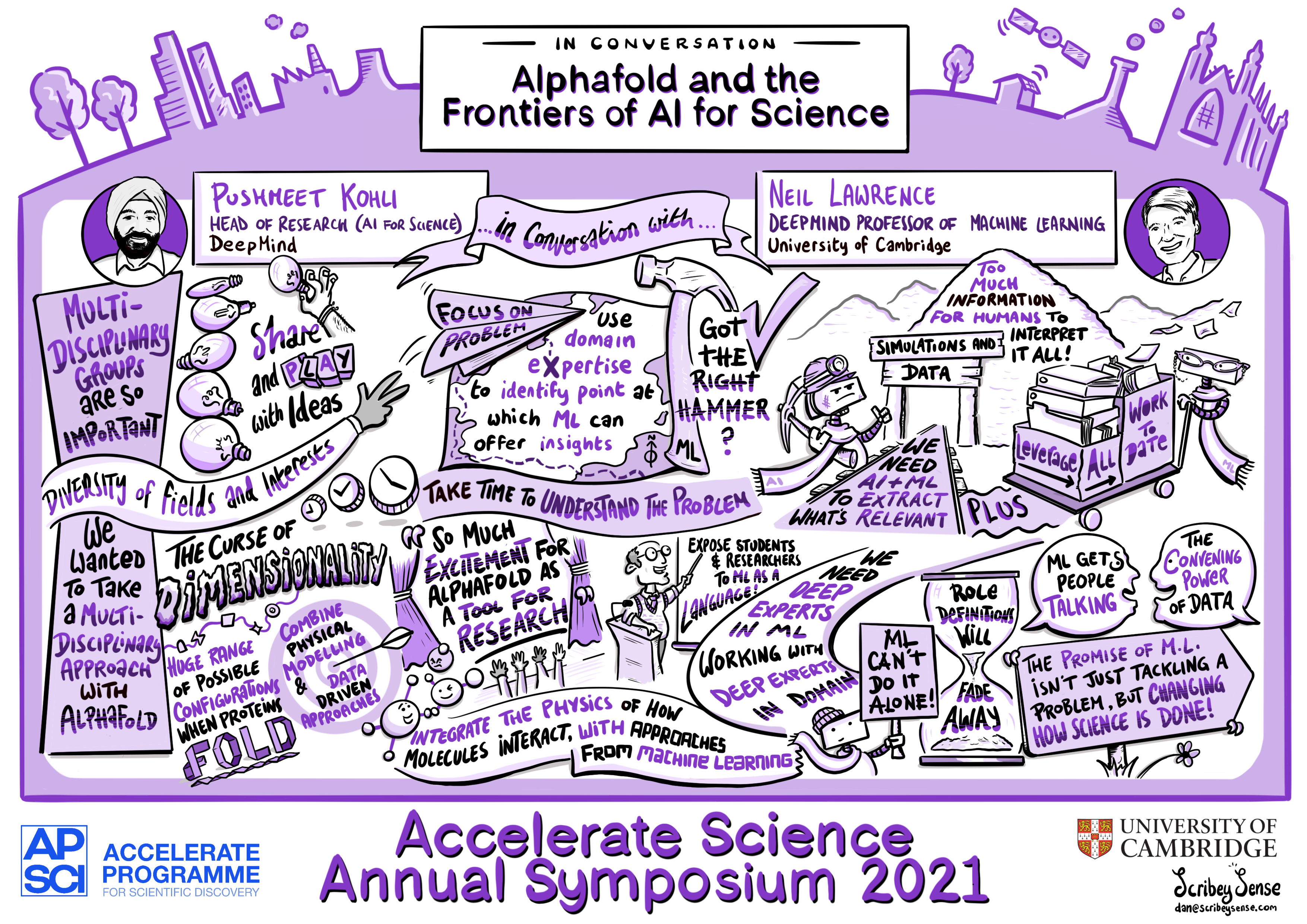
One of the highest profile successes in the use of AI for science in the last year has come from DeepMind’s AlphaFold project, which uses AI to advance scientific understandings of protein folding. In a fireside chat with Neil Lawrence, Pushmeet Kohli (Head of AI for Science, DeepMind) explained the importance of multidisciplinary collaborations in achieving its success. Protein shape and function are linked, and the ability to predict the shape of a protein would make an important contribution to efforts to understand and treat a range of diseases. Understanding how proteins fold is a long-standing scientific problem that research groups have been working on for many years. This previous research means that researchers already know the physical laws that determine how proteins fold, but even with this knowledge there is a huge number of different ways that a protein could fold before reaching its final configuration. The question for researchers is how to explore all those different configurations and predict the right one. Central to AlphaFold’s success is the combination of pre-existing knowledge about the physics of protein-folding with data-driven approaches. By internalising knowledge about the physical world, AlphaFold can leverage insights from data to predict protein structures more accurately. Combining physical and data-driven insights in this way requires interdisciplinary collaboration.
Such collaboration was on display across the Symposium’s unworkshops:
Thank you to Ramit Debnath, Markus Kaiser, Ieva Kazlauskaite, Bianca Dumitrascu, Challenger Mishra, and Sarah Morgan for convening unworkshop discussions, and to all the speakers for their contributions.
These discussions highlight the innovative ways in which researchers across Cambridge – and across research disciplines – are deploying AI to enhance their research. They also demonstrate the importance of interdisciplinary discussions in advancing the use of AI for scientific discovery.
This interdisciplinary approach harks back to the origins of the Cambridge Computer Lab. Under Maurice Wilkes’s leadership, the Lab set out to accelerate research through the deployment of new computer technologies; essentially to create a computer that could be used by scientists to advance their science. As Ann Copestake (Head of Department of Computer Science and Technology, University of Cambridge) explained at the Symposium, the computer they created was a game-changer: it enabled researchers to run experiments much faster than would otherwise have been possible, contributing to at least four Nobel Prizes awarded to Cambridge at the time. In the process, researchers began to use computing technologies to develop new theoretical approaches, contributing to the development of disciplines like computational linguistics.
There is an opportunity today to develop AI technologies along a similar pathway – from supporting data analysis to driving new types of theory. But the pace of change in AI’s capabilities – and in demand for AI across disciplines – is creating a disconnect between AI researchers and domain researchers. Accelerate is trying to bridge this gap, by building links between those developing and those using AI technologies, and by empowering researchers to deploy AI in their science. This will need new approaches to research and education to accelerate adoption of AI; but fundamentally it will require a renewed wave of interdisciplinary collaboration that creates shared understandings of the potential of AI and fosters new ideas across domains.
This was our first Symposium, and we’d like to thank everyone who contributed to discussions. We hope it marks the start of a continuing discussion across Cambridge about the potential of AI in science, and how the research community can harness this potential. Check out our event page for the event video.
Here is a graphic summary of the event: Event Summary
Our unworkshop on sustainability: Unworkshop summary - sustainability
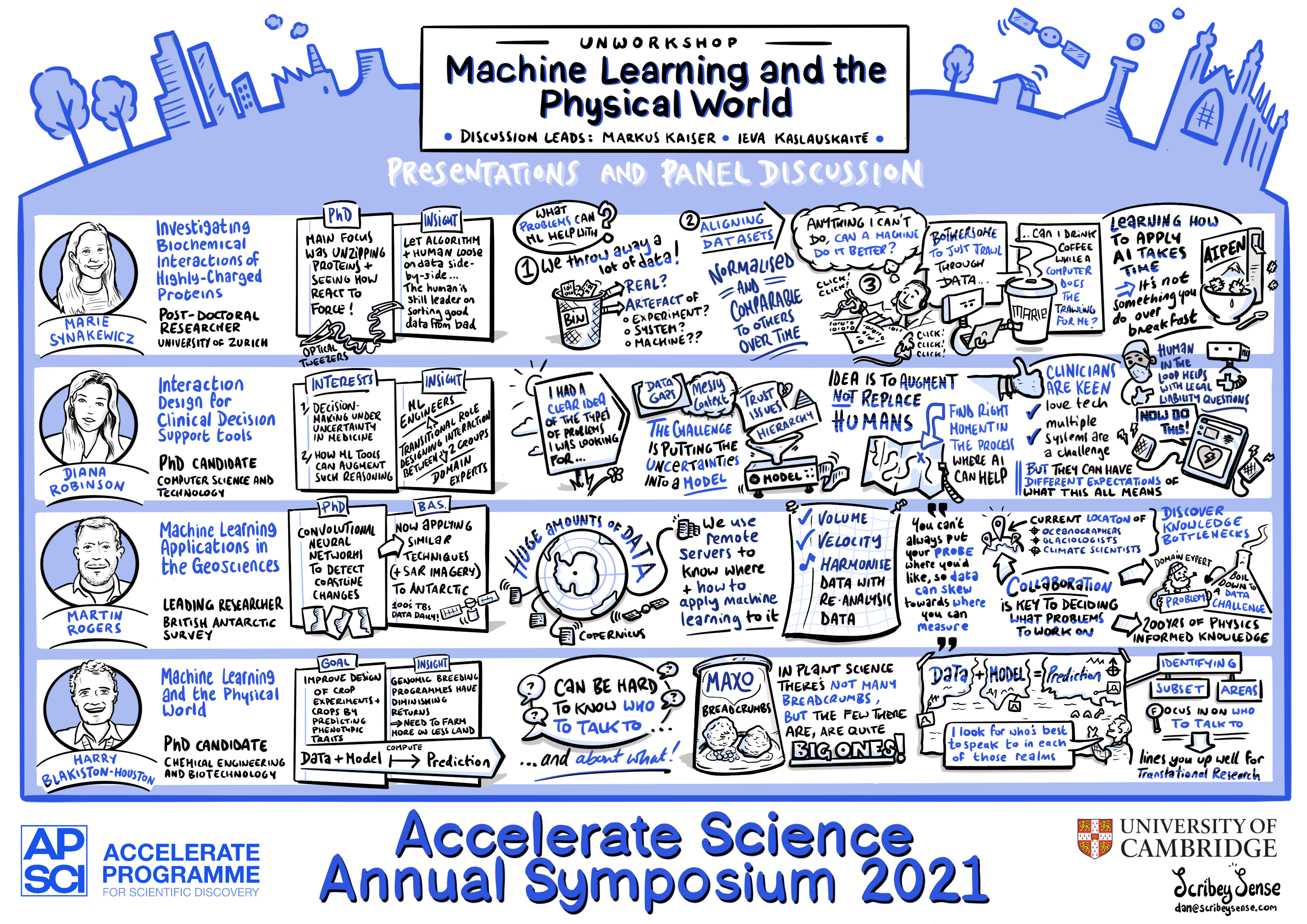
Our unworkshop on machine learning and the physical world: Unworkshop summary - physical world
Our unworkshop on challenges in science and maths: Unworkshop summary - science and maths
Our fireside chat about AlphaFold: Workshop summary - AlphaFold


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}